 , then
deal this node another card.
, then
deal this node another card.Whenever multiple processors exhibit different processing speeds, master/slave-type parallel codes can benefit from several types of dynamic load-balancing. Such load-balancing techniques apply to a wide variety of computing applications. Master/slave organization is similar to a card game in which a ``dealer'' distributes uniform sub-tasks to ``players,'' who perform the tasks. A Marginal Performance Rule, which evaluates the speed of each player against an ever-tightening performance threshold, is perfectly efficient, but locks up the game before all cards are dealt. An Expected Card Distribution algorithm can be used to estimate the number of cards that each player will process before the end of the game. Players expected to process less than one card are dropped to prevent them from holding up the finish of the game. Parallel codes using such well-mannered load-balancing techniques do their best to stay out of the way, and help to ensure that multiple users in a heterogeneous system will maximize the efficient use of the fixed computational resource.
Heterogeneous parallel computing environments are becoming increasingly common. Individual computing nodes functionally exhibit different processing speeds not only when they are of dissimilar types, but also whenever non-batch, multiple-user environments are permitted. The popularity of COWs (Clusters of Workstations), NOWs (Networks of Workstations), and Beowulf-class clusters has contributed to the increasing frequency of heterogeneous computing. Moreover, the linkage of clusters into hyper- or meta-configurations of multiple clusters, even when the processors internal to each (or all) cluster(s) are identical, functionally creates heterogeneity due to differential communication latency among certain pairs of nodes.
Perhaps the most popular general approach to parallel algorithms is the master/slave type of organization. In these multiple-tier applications, a single node (or more) functions to organize and disseminate the relatively separate tasks of the overall composite problem, and (optionally) to collect and/or reassemble the individual results into a single integrated answer or product. The class of nodes actually receiving and processing the smaller component tasks represent another specialized tier of this hierarchical approach. More than two tiers of organization are also possible. A single tier of ``slaves,'' all simultaneously running serial code with absolutely no inter-communication can be viewed as a specialized form of this approach. But two levels of organization, often with a single ``master'' node, is the most common configuration. Strategies for providing and optimizing load-balancing across multiple slave nodes within heterogeneous parallel environments is of general significance across a wide array of problems.
We have found it useful to conceptualize master/slave dynamic load-balancing problems in the form of a card game analogy, in which ``cards'' are viewed as uniformly-sized whole-integer pieces of the total problem. Cards are dealt by the master node to each of the slave nodes, which process them appropriately according to the particular application, and then place the results back on the table. The object in this analogy is to finish dealing and processing all cards in the deck as quickly as possible. In iterative applications, the ``players'' may have to go through the deck multiple times in a single ``game.''
In a perfectly homogeneous card game, in which all ``players'' are guaranteed to process cards at an equal speed, the optimum way to divide the deck is to have exactly as many cards as there are players. The dealer deals only a single round, and the game is over. Since all players are of equal speed, all finish synchronously, and no one waits idly. This simple strategy minimizes communication overhead between the players and the dealer, and results in the fastest processing of cards in the deck.
The optimum strategy for a heterogeneous game in which players process cards at different speeds is not so simple. First-order load balancing across multiple heterogeneous slaves can be achieved simply by over-dividing the deck. The dealer deals each player a single card, and still has cards left over in the deck. The first player to finish processing a card says ``Hit me,'' and receives another card from the dealer. Even such first-order load balancing represents a tremendous advantage in a heterogeneous computing environment, since the fastest (or least busy) players are able to do most of the work processing the deck. Still, an undesirable situation can be created if the last card (or one of the last) is given to a slow player. All of the faster players sit idle, waiting for the slowest player to finish processing the last card so that the game can end.
The dealer needs a way to evaluate whether or not to deal a card to a particular node, based on that nodes' past performance and the state of progress of the game. We have created an optimizing decision algorithm as follows:
If , then
deal this node another card.
If the expected marginal processing time for this node, based on past performance in this game, is less than the estimated time remaining in the game, the dealer should give this node the next card. Otherwise, this node is dropped from play, and the dealer evaluates the next available node. This player evaluation continues throughout the card-dealing process. The Marginal Performance Rule results in an ever-tightening performance criterion for players remaining in the game. As the number of cards remaining in the deck decreases, the slowest players are progressively dropped from the game. This rule precludes giving a slow player one of the last cards and holding up the game while the faster players wait for him.
The Marginal Performance Rule represents the definition of perfect efficiency, since it prevents the game from ever waiting on a player to finish. Unfortunately, this rule is too perfect; by definition, someone must get the last card, and the game must wait on that last player in order to finish. The ever-tightening Marginal Performance criterion eventually becomes so stringent that no players qualify, and the dealer simply sits, holding all of the remaining cards. The game locks up and stops without finishing.
The inevitability of this situation can be seen from the nature of the above equation. The left side of the inequality is player-specific, and decreases exponentially during the game, assymptotically approaching zero. The right side of the inequality is from the dealer's perspective, and decreases linearly to zero at the finish. Obviously, at some point before all cards are dealt, each player will fail the test and receive no additional cards.
Intuitively, we know that the last (several) cards should go to the fastest players. A safety test might keep the algorithm from ever dropping the last player, but this would not represent an optimized solution. We need to abandon the perfection of the Marginal Performance Rule in favor of a new algorithm in order to finish the game.
Another way to look at the problem is by asking, ``How many cards of
those that remain can we expect each node to process before the end of
the game?'' If the answer is one or more, then that node is allowed to
keep playing. Answering this question requires maintaining a sorted
array numdone containing the number of cards processed by
each player thus far. Then we can build a first-order linear
polynomial equation of the form
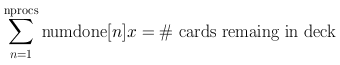
This expression forms a linear equation with an intercept of zero, whose composite summed slope represents an instantaneous measurement of the collective performance up to this point in the game. The individual slope terms from each node reflect the instantaneous performance of that node thus far.
One strategy is to let the game lock up using the Marginal Performance Rule, and then, for the few cards that remain, employ the above equation. We solve for x, and then multiply by each player's past performance term in order to obtain a floating-point estimate of the proportion of cards that this player will process of those remaining in the deck. By rounding to whole integers such that the total number of cards remaining is preserved, one can distribute the number of cards remaining over the players remaining, based on past performance.
This technique also provides a time evaluation of relative expected performance among alternative distributions of remaining cards over remaining players. If, for example, a node which has completed processing 20 cards thus far is expected to be given two cards, it should complete the task in 2/20 = 0.10 additional time units. The time to end-of-game is simply the longest such expected completion time for any player under a particular expected card distribution scheme.
Upon examining the individual node terms, any node projected to process less than one card is dropped from the game. Since we don't want to drop too many players, a more liberal cutoff threshold is < 0.5 cards. Because the projected number of cards processed is a floating point number, but cards are whole-integer units, we must recalculate the distribution of remaining cards over remaining players after having dropped some players from the game. Thus, the algorithm becomes
In the dynamic heterogeneous environment, however, the relative performance among players could change during this second phase of the game. Thus, even though we have a projection for how many cards should subsequently be processed by each node in the remainder of the game, it is best to simply restart the same first-order master/slave load balancing among all players making the ``cut,'' and finish the game. Thus, the dealer gives each remaining player a card, and keeps dealing them out as requested by players until they are gone.
A modified strategy would be to abandon entirely the Marginal Performance Rule, and rely on the card distribution technique, repeating that analysis after each card, or after, say, every five cards are dealt. It may be necessary to recalculate and drop players with increasing frequency as the game progresses toward the end.
In our full paper, we will analyze several combinations of these adaptive load-balancing strategies for relative performance in heterogeneous environments. In addition, we will model two related modifications to the card game: Rescission and Blacklisting. With Rescission, the dealer can call back a card and redeal it to another player if the first player takes too long to process it (or fails entirely). Rescission adds both performance optimization and fault tolerance to the game. Blacklisting permits the dealer to drop a very slow player from multiple ``hands.'' The dealer re-evaluates such blackballed players only after they are excluded for a pre-determined number of passes through the deck.
The self-optimizing load-balancing strategies discussed here result in shy and retreating codes which are well-mannered and promote peaceful co-existence by fleeing to relatively unused parts of heterogeneous computing environments. They have the ``nice'' property of doing their best to get out of the way. These run-and-hide characteristics are preserved even in complex hyper-cluster environments comprised of multiple parallel machines (i.e., connected via Globus), automatically taking into account the latency of distant connections to remote nodes. Such adaptive codes help to ensure that multiple users in a heterogeneous system will maximize the efficient use of the fixed computational resource, regardless of the behavior of the other users' code.
__________
*Oak Ridge National Laboratory, managed by Lockheed
Martin Energy Research Corp. for the U.S. Department of Energy under
contract number DE-AC05-96OR22464.
| "The submitted manuscript has been authored by a contractor of the U.S. Government under contract No. DE-AC05-96OR22464. Accordingly, the U.S. Government retains a nonexclusive, royalty-free license to publish or reproduce the published form of this contribution, or allow others to do so, for U.S. Government purposes." |