William W. Hargrove and Forrest M. Hoffman
THE FOLLOWING PROPOSAL IS TO BE CONSIDERED IN CONFIDENCE. PLEASE DO NOT SHARE OR CITE THIS DOCUMENT.
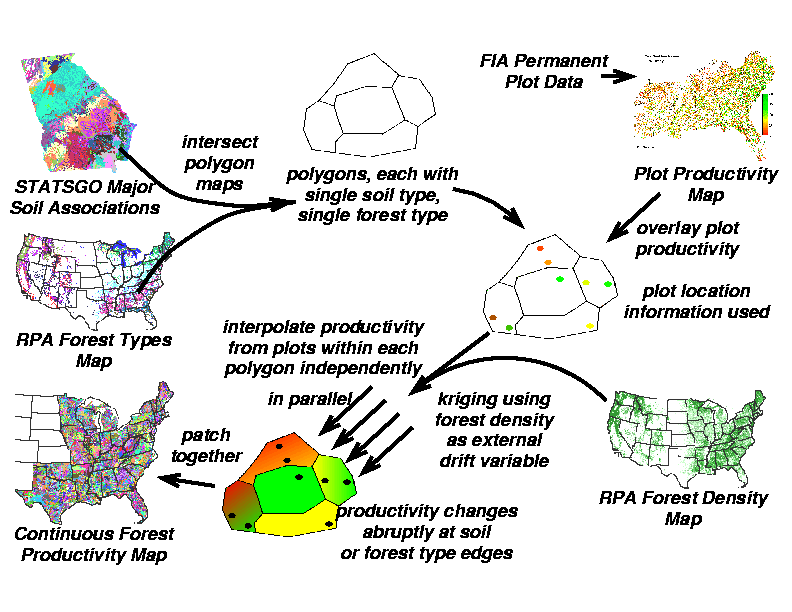
This proposal outlines a technique which employs the two premiere Forest Service databases, the Forest Inventory Assessment (FIA) and the Resource Planning Act (RPA) Assessment maps of forest type and forest density, in conjunction with soil types mapped from the national STATSGO database, to produce a continuous map of forest productivity across the southeastern U.S. at 1 km resolution. GIS intersection of STATSGO soils with RPA forest types produces a map of sub-polygons within each of which there is a single soil type and a single forest type. Forest productivity values from permanent plots that fall within individual sub-polygons can be adjusted for forest density within the 1 km cell, and then forest productivity can be interpolated across each individual sub-polygon. Because so many sub-polygons will be produced by the intersection of soil and forest type, interpolation of sub-polygons will be performed in parallel on a supercomputer. Because interpolation of individual polygons is completely independent, parallel interpolation will result in a linear increase in processing speed.
The continuous forest productivity map that results when the sub-polygons are patched back together, after correcting for forest density, can be used to produce estimates of total forest productivity across the southeastern United States. Unlike the original FIA data set, spatial statistics on forest productivity can be generated for any area, not just political boundaries, and take into account the spatial distribution of soils, and forest type and density.
Because the FIA and RPA datasets are iterative, the proposed technique could be employed backwards through time in order to investigate spatial and temporal changes in forest productivity across the southeast. The production of continuous maps of forest productivity from FIA and RPA datasets, if funded, would help to justify the continued Forest Service effort and expense of collecting such national datasets on forest growth and productivity.
Productivity of forests is of principal interest to taxpayers and stakeholders, yet cannot be remotely sensed and must be derived from direct measurements. The Forest Service Forest Inventory Assessment (FIA) program has established a series of permanent plots across the U.S. for the purpose of estimating productivity. A series of expansion factors allow for the multiplication of productivity within permanent plots up to projected values for counties, states, and regions.
However, if even a single plot is dropped from consideration for whatever reason (i.e., new plot, temporary plot, etc.), the supplied expansion factors are invalidated, and productivities can no longer be projected over larger areas. And, such "by multiplication" projections are not spatially-explicit; changes in forest productivity over space cannot be continuously seen within a single county or state. Finally, multiplication of plot productivity by an expansion factor ignores changes in soil and other environmental gradients between plot locations.
A continuous map of forest productivity which takes into account environmental, forest type, and soil gradients would be more valuable than the "spot productivities" provided by FIA permanent plots. Summary statistics could be calculated over any area, not just political boundaries of counties and states. Such a continuous map would not supplant projections obtained through simulation, but would augment them by providing an independent, direct measurement-based estimate of forest production for calibration and comparison.
Of course, one cannot simply interpolate productivity in a cavalier manner across FIA plots situated on different soils and growing different types of forests. However, careful interpolation of measured productivity from FIA plots within a single forest type growing on a single type of soil might produce acceptable results.
The proposed technique begins by intersecting the polygons from the RPA forest types map with the muid polygons representing major soil associations from the STATSGO data base. Each place where polygons overlap will be broken down into the smallest components created by the intersection, with both soil and forest type attributes preserved. The sub-polygons that result will be uniform with regard to soil type and type of forest cover. Because there are over 10 thousand soil muid polygons in the national STATSGO soil map, and because these will be further subdivided by the forest types, this intersection will likely result in a very large number of uniform sub-polygons.
FIA plot location information will then be used to overlay FIA plot productivities onto the sub-polygons. Because FIA plots are smaller in extent than the 1 km cell resolution, plot productivities will be linearly "transformed" according to the current percent forested cover for the cell in which the plot is located, as obtained from the RPA forest density map. Thus, the productivity value installed in the 1 km cell containing the plot is what would be expected if the entire 1 km cell were 100% forested.
Sub-polygons containing a single FIA plot will uniformly assume the "adjusted" value for that plot throughout the polygon. Sub-polygons containing more than one plot will be interpolated using a spline with tension. Although the figure refers to kriging using density as an external drift variable, there are not likely to be enough data points in most sub-polygons to permit construction of a semivariogram or fit a model. Thus, I propose to adjust the plot productivities up to full forest coverage for the occupied cells, and then spline a productivity gradient that would be present if the sub-polygon were 100% forested cover. As a final step, the RPA density map will be used to "back-transform" the productivity map to correct for less-than-100% forested cells.
Because there will be so many sub-polygons, the splining of the productivity will be done in parallel on a supercomputer with 126 nodes. Each node will spline adjusted FIA plot data across a single uniform soil/forest sub-polygon at a time. Since sub-polygons are completely independent of each other, this task is perfectly parallelizable, and will result in a linear decrease in processing time with additional nodes. When the sub-polygons are patched back together, the resulting productivity "quilt" will show abrupt discontinuities in forest productivity at the edges where sub-polygons meet. Although unusual, these abrupt changes are what we would expect (and require!) as we cross borders into different soils and/or different forest types.
The penultimate "quilt" map that results will reflect the forest productivity if forests were at 100% density across the map. This intermediate map product may itself be of interest to foresters, since it will show spatially where the greatest and least forest productivity is being achieved without the confounding effects of differences in forest density. As a final step, the current RPA forest density map will be used to linearly "back-transform" the complete-forest-coverage productivity values to correct for the proportion of each cell which is actually currently forested, according to RPA.
One potential problem will result if no FIA plots happen to fall in some fraction of the sub-polygons. Without a representative sample, it will be impossible to interpolate productivity within these areas, and this will result in "holes" in the "quilt" map. At the time of this proposal, there is no direct solution to this problem. Obviously, these uniform soil/forest type locations would be excellent candidates for the establishment of additional new FIA permanent plots.
However, if a large number of sub-polygons are without plots, one "tunable" option would be to lump together some of the separate forest types in the original RPA map. Fewer categories in one of the two starting maps should result in larger uniform soil/forest sub-polygons, each of which would be more likely to contain at least one FIA plot. The large number (53,300 FIA plots in the southeast) and overdispersed spatial arrangement of FIA plots should minimize this problem.
Another potential problem is that differences in stand age among plots will be confounded with differences in productivity in the final map. Because stand age data are supplied as ancillary data about FIA plots, it may be possible to subset plots within certain age classes. Alternatively, it may be possible to interpolate productivity in terms of some age-standardized measure like site index at 25 years old.
The generation of continuous maps of forest productivity as a useful, "value-added" derivative of FIA, RPA, and STATSGO national databases is plausible using the technique proposed here. Maps could be generated in terms of several alternative surrogates for productivity, including basal area increment, net cubic growth, or age-specific site index. Separate maps could be produced from various stratifications of the FIA data, i.e., conifer/mixed/deciduous, species-specific, managed vs. planted, etc. Finally, since RPA and FIA have been iteratively collected through time, the possibility exists for using this technique to generate a progression of productivity maps, so that spatial changes in productivity through time can be seen.
If funded, continuous maps of forest productivity produced using this technique will help to justify the tremendous effort and substantial fiscal investment that the Forest Service has made in the FIA and RPA programs in the past, and will leverage those efforts by coordinating with the national STATSGO database to help ensure the continued collection of FIA and RPA data in the future. The derived data product could be regenerated in parallel whenever significant changes occur to the FIA, RPA, or STATSGO databases.
The proposed deliverables are designed to integrate well with the RCLASS simulation output from the Integrated Modeling Project (IMP), and should provide an additional "yardstick" for comparison with IMP and other regional-scale productivity simulations. It may also be possible to "correct" productivity not only by RPA density values, but also by observed LAI values (8 sq. km resolution) provided by Ned Nikolov, thus interacting with another potentially-SGCP-funded project.
It is impossible to completely specify the non-loblolly productivity map, since our strategy is to lump RPA forest types and/or STATSGO soil taxonomic types in order to minimize "holes", i.e., uniform soil/forest sub-polygons which do not contain at least one FIA plot.
All maps will be provided as final products in digital form in ArcInfo or GRASS format via a WWW server. Selected maps may also be provided as wall-sized posters, since large scale visual examination of uniform sub-polygons is expected to be important for quality assurance.
We propose funding this work through the ORNL Computational Physics and Engineering Division (CPED). We anticipate that the project will take about 11 weeks of calendar effort for completion, but this effort will be performed over the next fiscal year.
| Start Date: February 1999 | ||
| Project Duration: 11 weeks | ||
| Due Date: October 15, 2000 | ||
| William W. Hargrove | Half-time effort over duration of proposed project - preparation of FIA data, overlay with RPA and STATSGO data, development of production splining macros, and harvest and quilting of uniform sub-polygons into final productivity maps: 20 hrs/week × 11 wks × $115/hr (w overhead) | $25,300.00 |
| Forrest M. Hoffman | Limited support for parallel implementation of uniform sub-polygon splining on Stone Soup parallel machine (computing cycles themselves are free): 4 hrs/week × 11 wks × $115/hr (w overhead) | 5,060.00 |
| Upgrade 4 nodes on parallel computer | 8,000.00 | |
| 1 18 Gb hard disk for workstation and 4 18 Gb disks for parallel machine - disks will be migrated to web server after proposed work is complete: 5 disks × $1,600/disk | 8,000.00 | |
| Plotter output media and lamination | 400.00 | |
| Conference travel | 3,000.00 | |
| Publication costs | 1,000.00 | |
| TOTAL COSTS | $50,760.00 | |
For additional information contact: