A New High-Resolution National Map of Vegetation Ecoregions Produced Empirically Using Multivariate Spatial Clustering
William W. Hargrove and Robert J. Luxmoore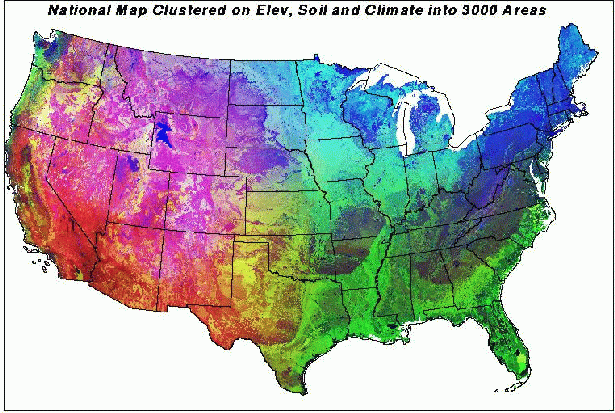
A parallel supercomputer was used to divide the conterminous 48 states of the United States into 1000, 2000, 3000, 5000, and 7000 ecoregions with relatively homogeneous values of elevation, edaphic, and climatic variables using an iterative multivariate clustering technique. Resolution of the clustered maps is 1 square kilometer; each national map has over 7.7 million cells. Each cell has nine variables from maps with values for elevation, soil nitrogen, soil organic matter, soil water capacity, depth to water table, mean precipitation, solar irradiance, degree-day heat sum, and degree-day cold sum.
The resultant national maps objectively capture the ecological patterns of spatial variance in physical, edaphic, and climatic factors relevant for the distribution and growth of plants and animals. Assignment of red, green, and blue colors according to the principal component scores associated with the ranges of the nine variables defining each cluster results in a map where the ecological similarity of adjacent cluster regions is readily apparent. Maps with this gradually-changing color spectrum illustrate ecological relationships for plant growth derived from soil factors, physiognomy, and climate across the 48 states at user-defined resolutions. The clustering technique is being used as a way to spatially extend the results of simulation models by reducing the number of runs needed to obtain output over a larger area.
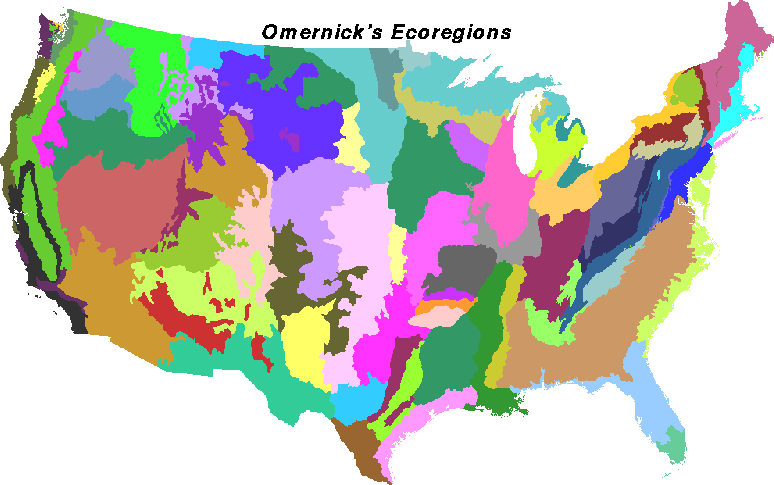
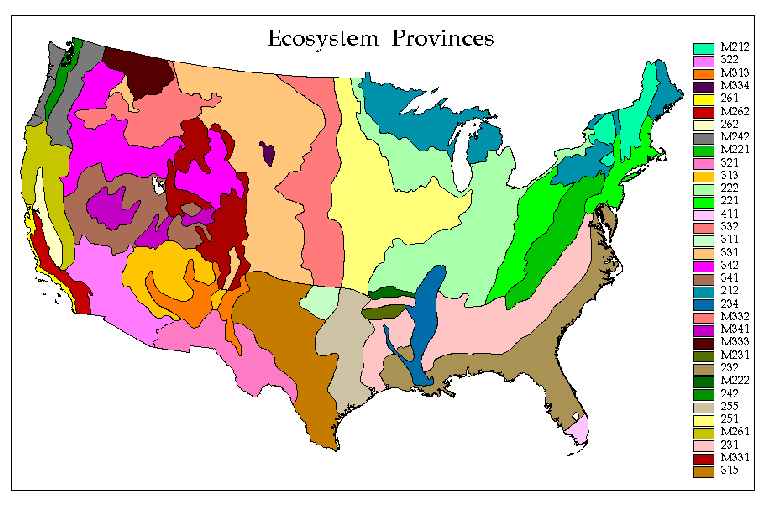
Ecoregions have proven to be a useful concept to ecologists, and many variants of ecoregions have been developed. Omernick's 1987 aquatic ecoregions were based on perceived patterns of land use, land surface form, potential natural vegetation, and soils. Although delineated for national-level studies of water resources, Omernick's 76 national ecoregions have been borrowed for many other kinds of ecological studies. Bailey (1995, 1996) delineated 52 ecoregions at the finest province level, increased from 30 in his original Bailey (1983) version. The Forest Service ECOMAP effort is currently striving to break Bailey's divisions into finer-scale pieces. Other, different ecoregions, based on other criteria and for other purposes, have been specified by Kuchler, Holdridge (1947), Walter and Box, Thornwaite, Koppen, and many others. Because the delineation is based on subjective criteria, there are as many sets of ecoregions as there are experts.
An alternative to maps based on expert opinion is the use of more empirical and repeatable data analysis techniques for defining ecoregions. Yet obviously no single set of division criteria or scale of divisions will suffice for all ecological uses. Such a technique would encourage a proliferation of ecoregion divisions, each customized for a particular purpose.
Image classification is a well-known form of custom grouping, based
on reflection characteristics, which results in the delineation of
similar areas within an image. The ArcInfo function
ISOCLUSTER uses a clustering technique on sampled subsets
of cells to develop reflectance signatures for subsequent image
analysis and classification. However, the technique has rarely been
applied to primary, non-spectral data outside traditional image
classification. Omi et al. (1979) used multivariate map clustering on
primary variables including steepness, drainage, precipitation, and
fault density to demarcate fire management planning zones in the
Angeles National Forest in California.
Our objective is to create custom geographic ecoregions which are homogeneous with regard to the growth of woody vegetation. Our ecoregions are based on multivariate geographic clustering of 9 variables important to tree growth in 3 groups - elevation, soil or edaphic factors, and climatic factors. Within soil factors, we have maps of plant-available water capacity, soil organic matter, total Kjeldahl soil nitrogen, and depth to seasonally-high water table. The climatic maps include mean precipitation during the growing season, mean solar insolation during the growing season, degree-day heat sum during the growing season, and degree-day cold sum during the non-growing season. The growing season is defined by the frost-free period between mean day of first and last frost each year.
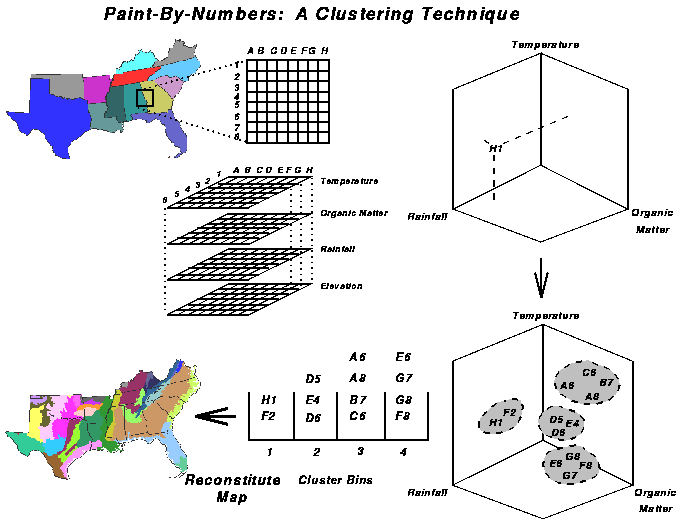
Maps of each of the nine input variables were generated for the continental United States, each containing 7.7 million cells at 1 km resolution. The geographic multivariate clustering process begins in geographic map space with the nine input maps, then enters statistical data space for the multivariate analysis, and emerges back from data space into geographic space when the final map is re-assembled.
The stack of 9 co-registered maps is disassembled into its component 1-km cells, while retaining the x,y position information for later re-assembly. Each cell, along with its 9 variable values, now becomes an observation in the multivariate statistical analysis. Although we use GRASS (1993), ArcInfo GRID, Spatial Analyst, or any other raster-based GIS may be used.
The nine values are used as coordinates to specify a particular location for each of the 7.7 million sq km cells in a 9-dimensional data space (only 3 dimensions can be shown here). Then, using an iterative convergent procedure running on a parallel supercomputer, we divide groups of nearby, similar cells into a selected number of ``clouds'' until each of the 1 sq km cells has a cluster assignment. Cells are separated into as many discrete clouds of pixels with similar combinations of values of the 9 initial variables as the user has requested. If more clusters are requested, the variance within each cluster decreases. Finally, the pixels, with their cluster assignments, are re-integrated and assembled back into the map, color-coded by cluster number. Because cells with similar suites of variables that are nearby in data space are also likely to be near each other in geographic space, clusters often form contiguous groups of cells in the final map.
A principal component analysis is performed on the nine variable
values associated with each pixel to remove correlations among the input variables, to
standardize the mean and variance, and to reduce the dimensionality of
the nine original variables to three principal component factors. The
k-means clustering algorithm (MacQueen 1967) iteratively
changes the cluster assignment of cells until a convergence criterion
is met, and then the map is rebuilt.
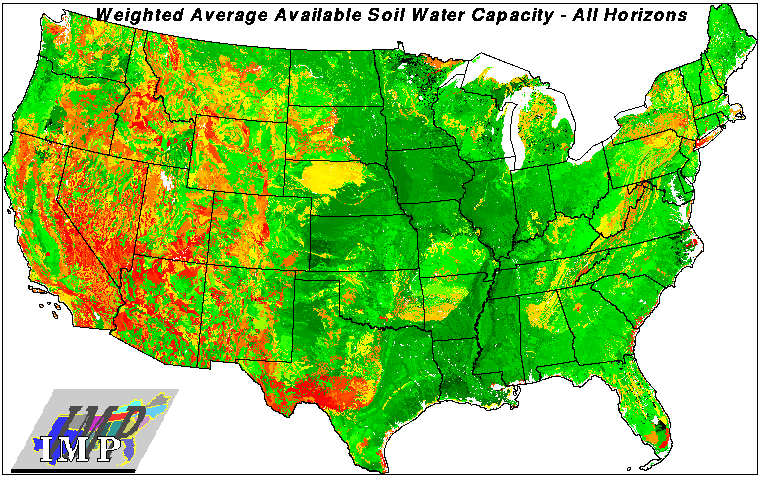
This is the map of plant-available soil water capacity, which is the difference between field capacity and wilting point. These data are from the national STATSGO database, developed by the Natural Resources Conservation Service. Soil water data are mapped by integrating downward through all soil horizons in each pedon, and then doing a weighted spatial average over each area component of each soil association polygon. There are over 10 thousand soil polygons in the entire map. Soils in the midwest (centered in Iowa) and in the south have the greatest soil water capacities.
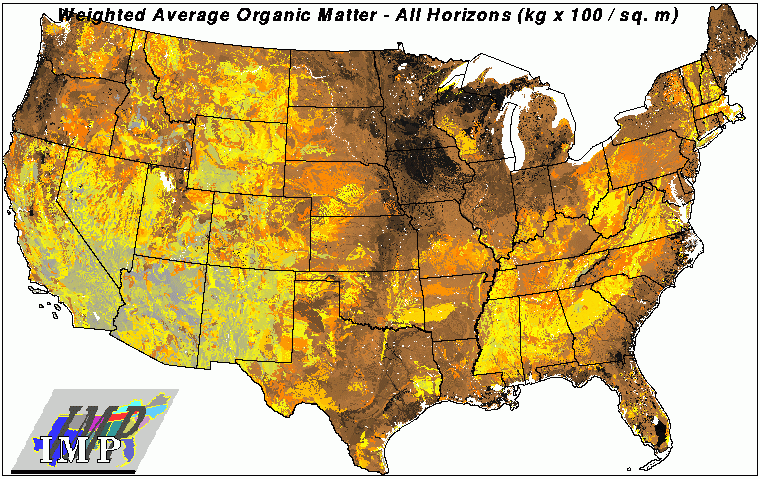
A national map of total organic matter in soil was also developed from the STATSGO database. The color scale ranges from gray sandy soils to dark brown loamy organic peats. Again the midwest stands out, and so does the Okefenokee swamp in south Georgia and the Everglades of Florida.
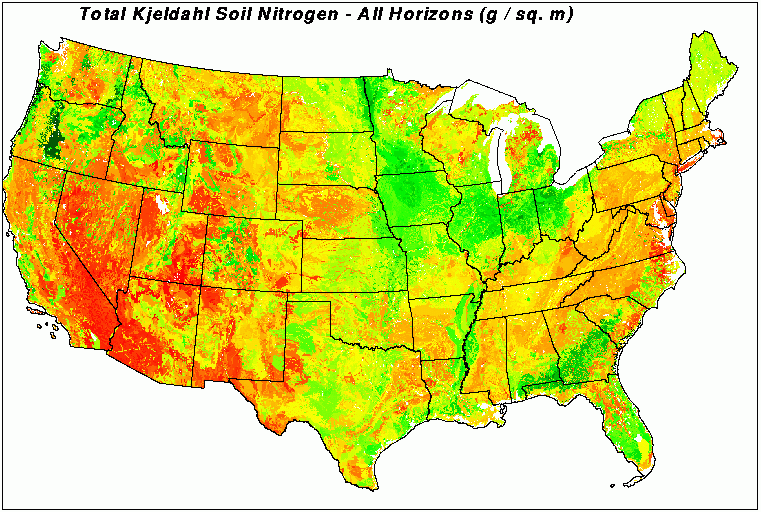
A national soil nitrogen map at 1-km resolution was developed from the May 1994 National Soil Characterization Database, linked back to the spatial information in STATSGO using soil taxonomic relationships. Soil nitrogen is high in the deep Mollisols of the midwest and in the Pacific Northwest.
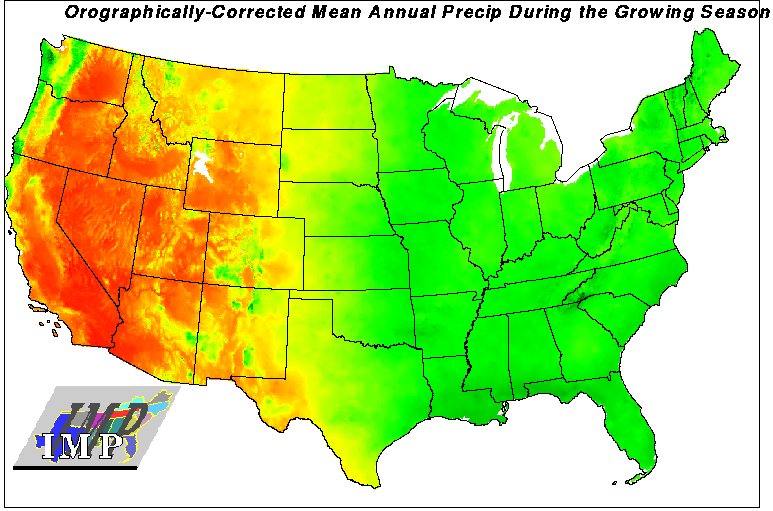
Orographically-corrected monthly mean precipitation from Chris Daly's PRISM model gives monthly rainfall equivalent at 4x4 km resolution which has been corrected for elevation effects. Monthly values of corrected precipitation are averaged over the days in the growing season for each cell in the map, so that southern cells are averaged over more months than northern cells, for example. The growing season is defined by the frost-free period, and months are linearly prorated for days when the month is not completely frost-free. Rainfall during the active growing season may be most important to growth of vegetation.
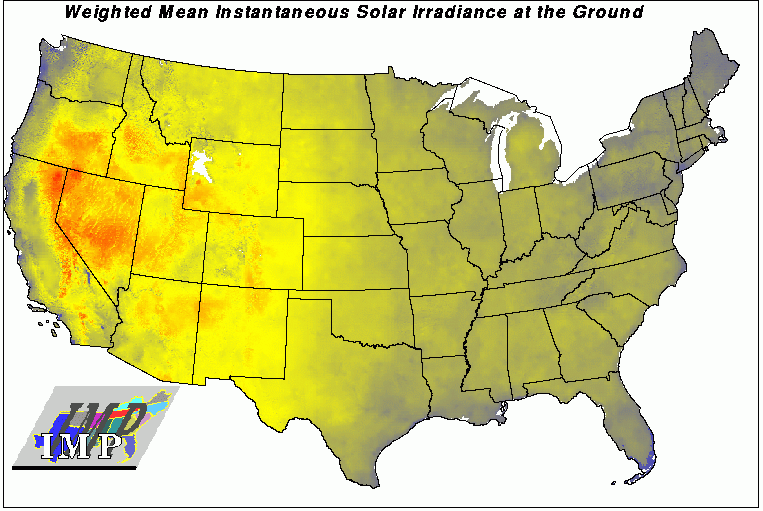
This is mean solar irradiance at the ground, from 2 data sources. The first source is NASA GISS data from the ISCCP satellite over 7 years, which includes interception by cloud cover and water vapor; the Pacific Northwest, for example, has relatively low irradiance. This source predicts solar energy interception by a flat plane oriented perpendicularly to latitude. This 1x1 degree map was splined to 20x20 km resolution before use. The second source is the Swift (1976) solar F algorithm, which uses the latitude, slope, and aspect at each cell in the map to calculate the ratio of flat plane solar interception to that of a surface oriented at the actual aspect of the cell. Aspect and slope are calculated from the North American portion of the GTOPO30 global elevation data set. This input map layer is also a weighted mean over the duration of the frost-free growing season at each cell in the map, assuming that it is the solar energy available to vegetation during the growing season that is important to plant growth.
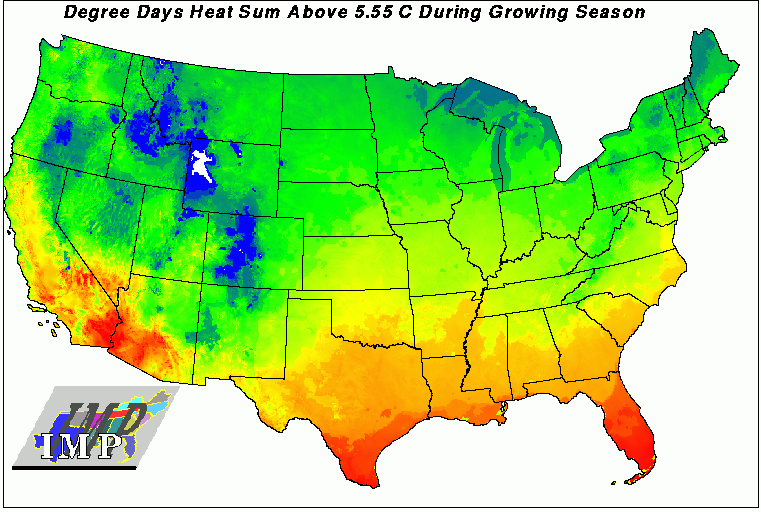
This map is a degree-day heat sum above a threshold temperature of 5.55 degrees C, summed only over the growing season at each location - a seasonally-weighted degree-day map.
A series of 12 monthly national mean temperature maps are initially produced at 1-km resolution to generate the degree-day maps. A parallel supercomputer running a regularized spline with tension and smoothing produced one national monthly mean temperature map at each of 12 nodes. Monthly maximum and minimum temperature maps were also generated.
The U.S. National 1961 - 1991 Climate Normals, measured at 4,761 National Climatic Data Center meteorological stations, are the initial source of data for the monthly temperature maps. To account for elevation effects on temperature, the adiabatic lapse rate, along with the station elevation from GTOPO30, is used to ``correct'' the temperatures measured at the station to an equivalent value for a weather station at mean sea level.
Because the adiabatic lapse rate depends on the amount of moisture in the air, the mean monthly afternoon relative humidity at a number of weather stations is interpolated to generate monthly maps of average relative humidity across the nation. Adiabatic lapse rates are then spatially and temporally (monthly) customized for the sea level adjustments at each location according to the elevation and appropriate humidity conditions at each cell.
National monthly maps are interpolated on these ``sea-level'' temperatures, and then temperatures at each cell in the maps are once again ``corrected'' back to the appropriate elevation from GTOPO30 using spatially and temporally customized adiabatic lapse rates. A weighted-average of monthly mean temperatures over the frost-free growing season are calculated at each cell in the map to produce the degree-day maps.
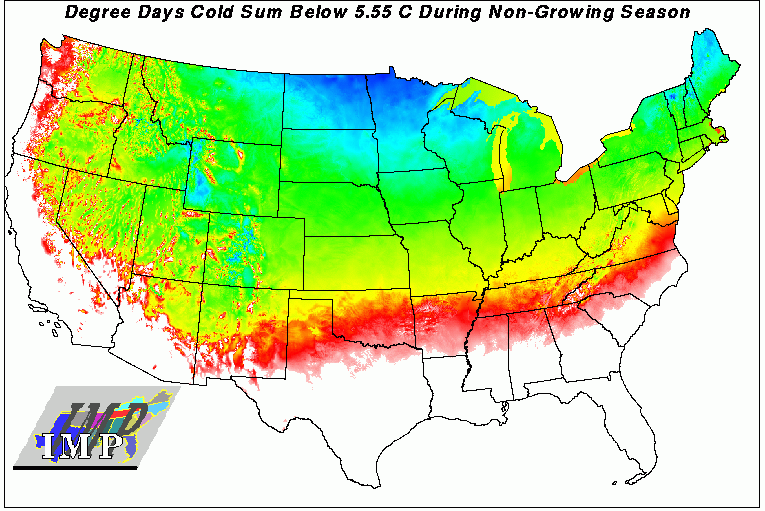
This map of degree-day cold sum below a 5.55 degree C threshold temperature is the converse of the last one, yet the two variables contain distinct information. Unlike the heat sum map, the cold sum map is averaged over the non-growing season. Plants are affected by temperature while they are growing, but also by how cold it gets while they are dormant.
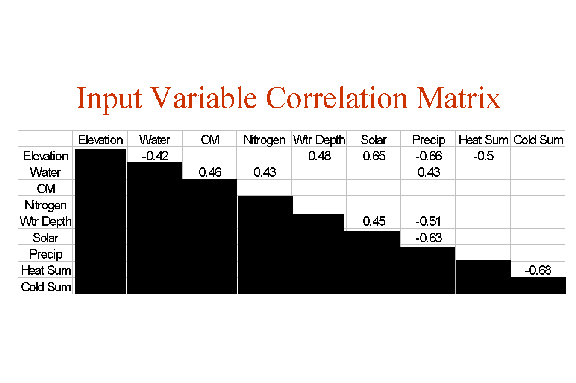
Principal component analysis on these nine input variables shows that 3 principal component factors explain more than 98% of the variance, and the variables load nicely on each factor, making them interpretable. Factor 1 is mostly associated with solar and elevation, with some influence of precipitation and water table depth - a sort of physiographic axis. Notice that precipitation is inversely related to depth to water table. Factor 2 loads with soil water, organic matter, and nitrogen, making Factor 2 essentially a soil resource axis. Factor 3 is heat and cold sums, inversely loading to create a thermal axis.
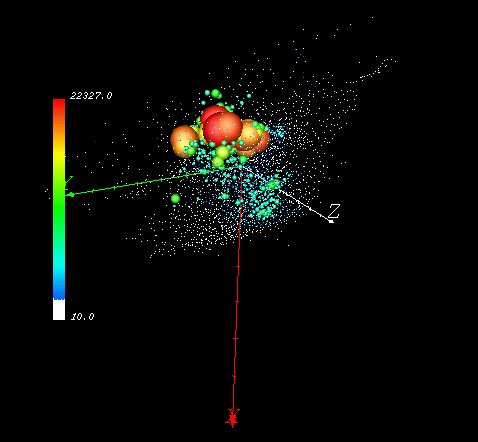
This is how the United States appears when clustered in ecological 3-space defined by the three principal component axes collapsed from the nine input variables. Each spot in this data space represents a mean centroid for one of 3000 clusters, and, in this visualization, the size and color of each of the centroids relates to how many of the 1-km cells are members of this cluster. The largest cluster is 22 thousand square kilometers, and the size distribution of clusters is a negative exponential. The largest cluster ``galaxies'' are close to the center of the data ``universe''. We have repeated this national clustering 5 times, requesting 7000, 5000, 3000, 2000, and 1000 output cluster ecoregions - much finer spatial divisions than provided by classical ecoregion maps.
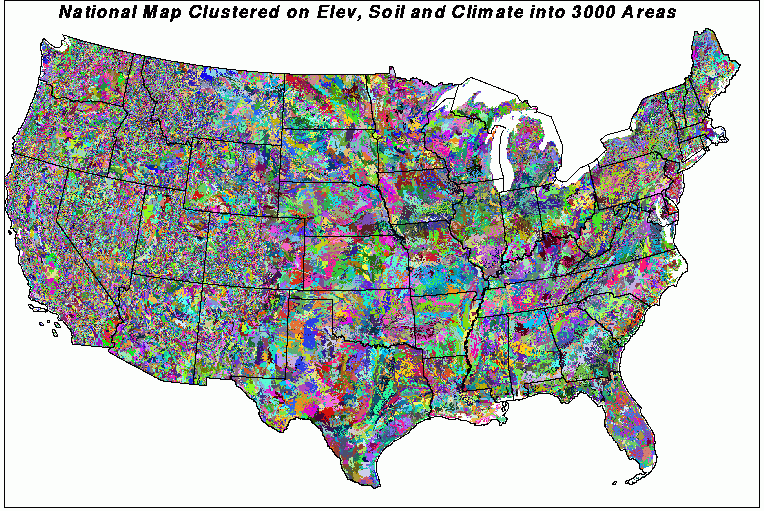
This is how the United States appears divided into 3000 ecoregions based on elevation, soil, and climate. This many homogeneous ecoregions are somewhat overwhelming at this scale. Clusters tend to be larger in the central U.S. than other places. Examination of these 3000 ecoregions at smaller scales makes them much more interpretable. Still, we may wish for a way to color clusters not just randomly, but so that each of the colors reflect the values of the input variables within each cluster.
We have 3 principal component factors, and 3 color guns. If we map the 3 factor coordinates at the centroid of each cluster to each color gun, we can create a unique RGB color for each cluster ecoregion which reflects the principal component contributions of variable values within it. Now the map will show the relative importance of each of the 3 suites of variables at each cluster.
Based on the principal component factor loadings, the redder a cluster appears in this map, the higher solar input and elevation, and the drier. Greener areas are lower in soil organic matter, nitrogen, and water-holding capacity. Bluer areas are decreased heat sum, increased cold sum, i.e., colder. So red is hot and dry, green is poorer soil, and blue is cold.
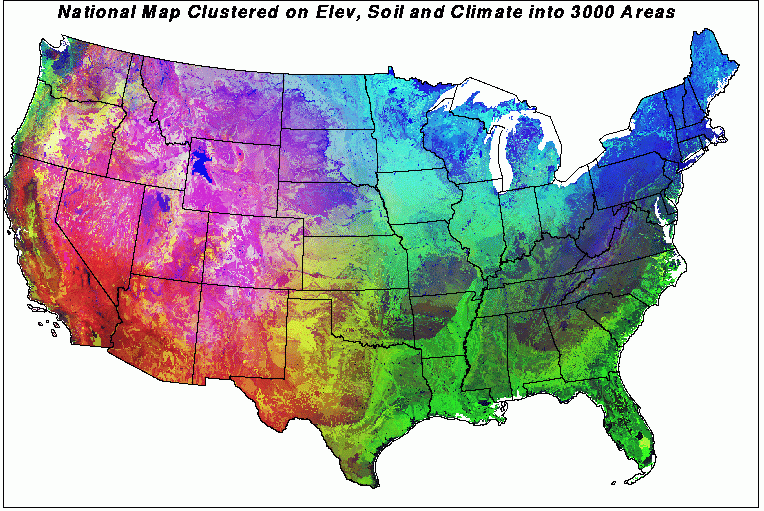
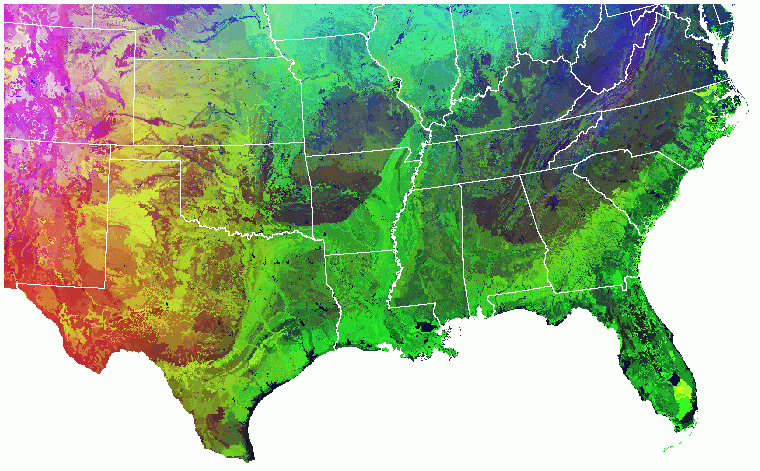
This is the way that the national map of multivariate vegetation patterns appears under the new RGB color scheme. The individual clusters essentially merge with neighbors, and the map changes into a spectrum of color gradients which reflect the dominant suites of variables affecting vegetation growth in each region of the country. The red Southwest is dominated by physiographic factors. The blue Northeast is dominated by thermal factors. The green Southeast has rather poor soils, on the whole. The upper midwest is very light blue because of the cold continental winter. The Pacific Northwest and the Central California valley are light green - fairly favorable conditions for plants.
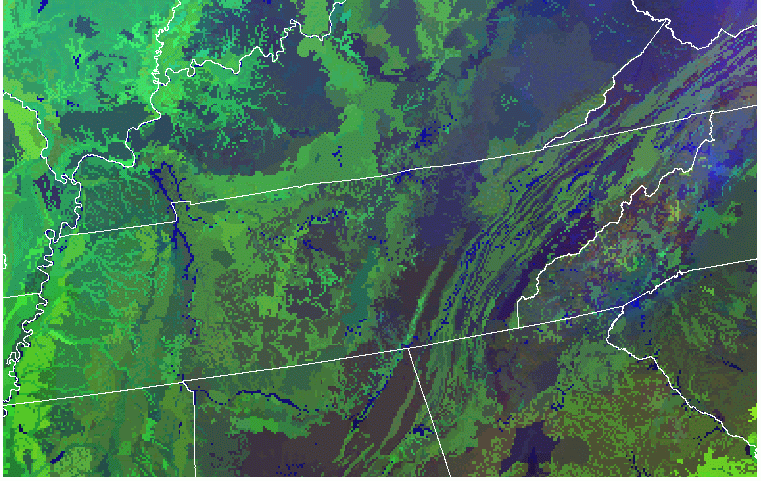
If we start to zoom in on the Southeast, we can see the Fall line/Atlantic flatwoods, the Coastal Plain, the Piedmont, the Arkansas Blacklands, and the Ozarks. If we continue to zoom on Tennessee, the whole state appears as shades of green, but we can still see (from east to west) the Appalachians, the Ridge and Valley province, the colder (bluer) Cumberland plateau, the Nashville Basin, the Highland Rim/Pennyroyal plain, the Mississippi uplands, and the fertile light green alluvium of the Mississippi valley.
If we switch back to a random color scheme, we are looking at the same polygons as the last Tennessee map, just colored differently. We're still not close to the full 1-km resolution. There are many clusters in eastern Tennessee, due partly to the elevation gradients present there.
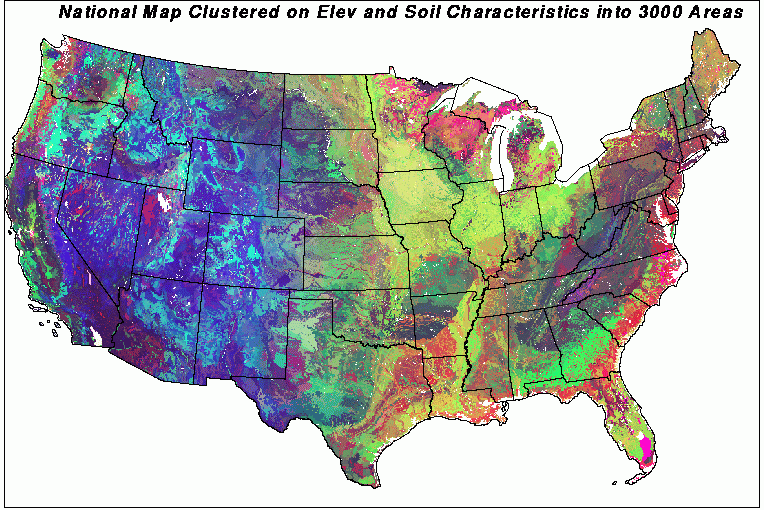
Now what does the United States look like if we drop the climate variables and only consider elevation and soil factors? Quite different; now spots in Southern Louisiana, Wisconsin, and Maine are all the same color - the same elevation and soil characteristics - but when we included climatic factors, all of these spots diverged radically.
To see any of the cluster maps in more detail, go to http://www.esd.ornl.gov/projects/clustering/.
The Wisconsin Department of Natural Resources has assembled detailed maps of 4 alternative versions of ecoregions for the state of Wisconsin: Omernick's (1987) ecoregions, Albert's (1995) Regional Landscape Units, Bailey's (1984) ecoregions, and Hole and Germain's (1984) Natural Divisions. Wisconsin was clipped from our national map clustered on the nine factors into 1000 pieces; the coarsest clustering we performed. The four existing alternative ecoregion maps for Wisconsin were overlain as vector lines on top of our randomly-colored cluster ecoregions. Although more finely divided than any of the extant ecoregion schemes, many of the borders of the multivariate vegetation clusters are shared with Albert's, Bailey's, and Hole and Germain's ecoregions. Only Omernick's divisions are a poor fit.
Interestingly, when the RGB color scheme is applied to any of the cluster maps (i.e., the 7000, the 5000, the 3000 cluster results, etc.), the resultant maps are visually indistinguishable. The national color pattern is the same, even though the underlying ecoregion polygons are completely different. All maps converge on a single picture of the ecological relationships among the variables. This suggests that, after the United States is divided into more than 1000 ecoregions, we have captured most of the national-scale spatial variance in vegetation patterns.
Multivariate geographic clustering can be used as a way to spatially extend the results of simulation models by reducing the number of runs needed to obtain output over a larger area. Simulation models can be run on each relatively homogeneous cluster rather than on each individual cell. The clustered map can be populated with simulated results cluster by cluster, like a paint-by-number picture. This cluster fill-in simulation technique will be used by the Integrated Modeling Project to assess the health and productivity of southeastern forests.
This multivariate geographic clustering technique has several advantages. Clustering is data-driven and empirical. One obtains the same result every time, given the same data and a request for the same number of clusters, in contrast to regions drawn by expert opinion. Users control what data are included for consideration in the clustering process based on what is appropriate for their purposes. Users are also able to select how many homogeneous regions are produced in the final clustered map. Finally, any eclectic combination of continuous variables can be combined to form homogeneous areas on a map.
The US Forest Service, Southern Global Change Program supported this work through the Integrated Modeling Project. W. Mac Post was instrumental in the development of the soil nitrogen layer. John Laedlein developed and provided the coverages of the four alternative ecoregion divisions for Wisconsin. Andrew Schultz encoded the parallel clustering algorithm. Forrest Hoffman coded the pan/zoom/scroll map web tool, helped with the parallel clustering algorithm, and was the prime mover in the construction of the parallel supercomputer.
Albert, D.A. 1995. Regional Landscape Ecosystems of Michigan, Minnesota, and Wisconsin: A Working Classification, United States Department of Agriculture, Forest Service, North Central Forest Experiment Station. St. Paul, Minnesota, 1995. General Technical Report NC-178.
Bailey, R.G. 1983. Delineation of ecosystem regions. Environmental Managemant 7:365-373.
Bailey, R.G., Avers, P.E., T. King, W.H. McNab, eds. 1994. Ecoregions and subregions of the United States (map). Washington, DC: U.S. Geological Survey. Scale 1: 7,500,000; colored. Accompanied by a supplementary table of map unit descriptions compiled and edited by McNab, W.H., and R.G. Bailey. Prepared for the U.S. Department of Agriculture, Forest Service.
Bailey, R.G. 1995. Description of the ecoregions of the United States. (2nd ed., 1st ed. 1980). Misc. Publ. No. 1391, Washington, D.C. U.S. Forest Service. 108 pgs with separate map at 1:7,500,000.
Bailey, R.G. 1996. Ecosystem Geography. Springer-Verlag. 216 pgs.
Daly, C., R.P. Nielson, and D.L. Phillips. 1994. A statistical-topographic model for mapping climatological precipitation over mountainous terrain. Journal of Applied Meteorology 33:140-158.
GRASS 4.1 Reference Manual. 1993. U. S. Army Corps of Engineers, Construction Engineering Laboratories, Champaign, Illinois, p. 422-425.
Holdridge, L.R. 1947. Determination of world plant formations from simple climatic data. Science 105:367-368.
Hole, F.D., and C.E. Germain. 1994. "Natural divisions of Wisconsin." Map. Madison, WI: Wisconsin Department of Natural Resources.
MacQueen, J.B. 1967. Some methods for the classification and analysis of multivariate observations. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability 1:281-297.
Omi, P.N., L.C. Wensel, and J.L. Murphy. 1979. An application of multivariate statistics to land-use planning: classifying land units into homogeneous zones. Forest Sci. 25(3):399-414.
Swift, L.W., Jr. 1976. Algorithm for solar radiation on mountain slopes. Water Resources Research 12(1):108-112.
Research sponsored by United States Forest Service, Southern Global Change Program under interagency agreement with U.S. DOE. Research conducted at Oak Ridge National Laboratory, managed by Lockheed Martin Energy Corp. under contract DE-AC05-96OR22464 with U.S. DOE.
"The submitted manuscript has been authored by a contractor of the U.S. Government under contract No. DE-AC05-96OR22464. Accordingly, the U.S. Government retains a nonexclusive, royalty-free license to publish or reproduce the published form of this contribution, or allow others to do so, for U.S. Government purposes."
For additional information contact:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}