A Spatial Clustering Technique for the Identification of Customizable Ecoregions
William W. Hargrove and Robert J. Luxmoore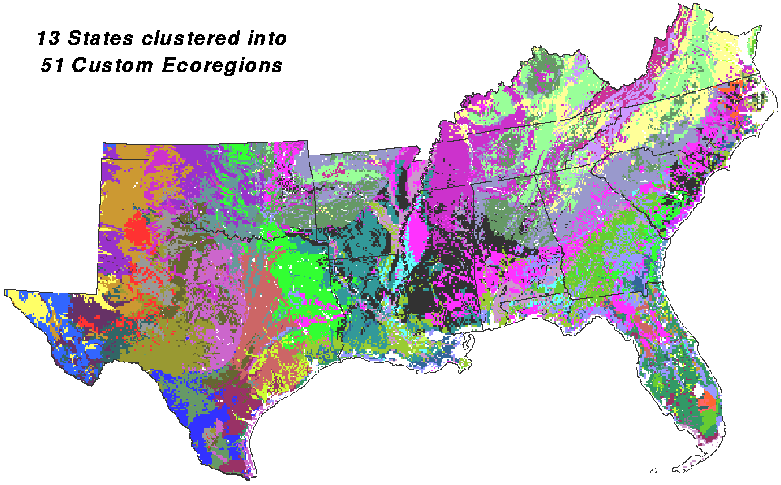
A geographic clustering technique is described which links a GIS with a statistical analysis package, SAS, in order to create any number of user-customizable ecoregions at any scale. Each of the ecoregions will be relatively homogeneous with regard to the combination of variables used to generate them. The number of final clusters is under users' control, so that patches in the final map can be made coarse or fine.
A spatial clustering technique was used to identify patches which are similar with regard to six edaphic and physiographic variables. A single state (TN) and a five state area (KY, TN, VA, NC, SC, and GA) at 1-km resolution, and a 13 state southeastern region at 5-km resolution were successively divided. 50-year mean monthly temperature, 50-year mean monthly precipitation, elevation, total plant-available water content of soil, total organic matter in soil, and total Kjeldahl soil nitrogen were used as input classification variables.
The maps were disassembled into cells, each with values for the six environmental variables, and the cells were submitted to a factor analysis and equamax axis rotation using the SAS procedure
FACTOR. The factor analysis removes correlations from the input variables, reduces the dimensionality, and normalizes the axis measurements.A cluster analysis was performed on the three principal factor scores using the SAS procedure
FASTCLUS, and the cells, with their cluster assignments, were re-integrated into the map. A series of maps dividing the 1-, 5-, and 13-state areas into a number of custom ecoregions are presented, and these custom regions are compared with the Major Land Resource Areas (MLRAs) identified by the National Resources Conservation Service (NRCS) within these states. The resultant custom maps can be used like a paint-by-numbers picture to extrapolate measured or simulated data over space.This work has been sponsored by the U.S. Forest Service Southern Global Change Program. The Integrated Modeling Project (IMP) will use this multivariate geographic clustering technique to scale up physiologically-based individual tree models to a 13-state area in order to make assessments of the future state of southeastern forest resources.
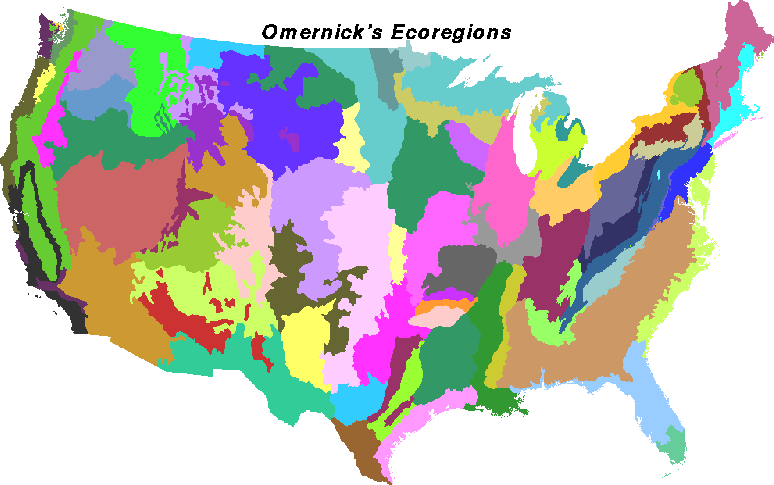
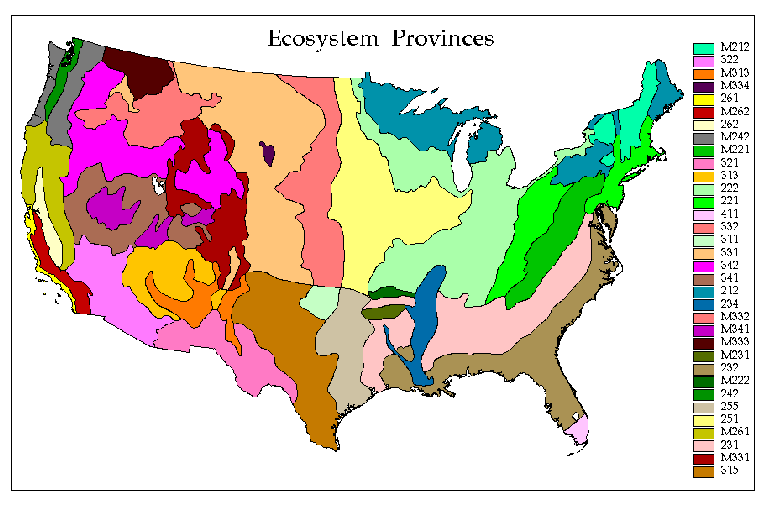
Ecoregions have proven to be a useful concept to ecologists, and many variants of ecoregions have been developed. Omernick's 1987 aquatic ecoregions were based on perceived patterns of a combination of causal and integrative factors, including land use, land surface form, potential natural vegetation, and soils. Although delineated for national-level studies of water resources, Omernick's 76 national ecoregions have been borrowed for many other kinds of ecological studies as well. Bailey (1995, 1996) delineated 52 ecoregions at the finest province level, increased from 30 in his original Bailey (1983) version. Other, different ecoregions, based on other criteria and for other purposes, have been specified by Holdridge (1947), Walter and Box, Thornwaite, Koppen and many others. Because the delineation is based on subjective criteria, there are as many sets of ecoregions as there are experts.
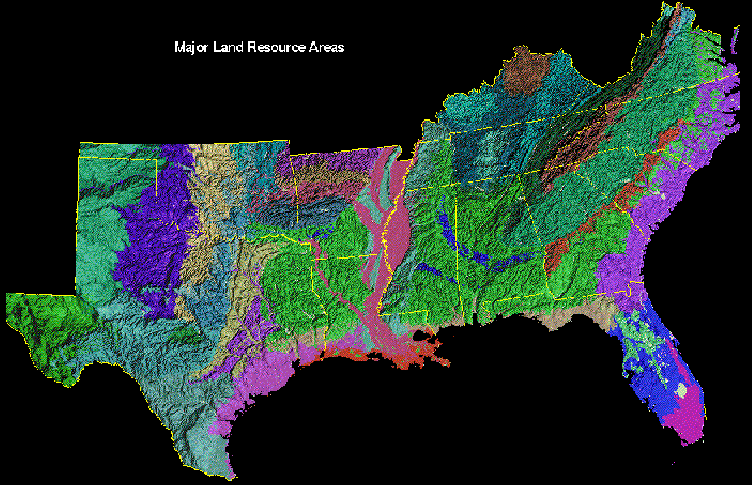
The National Resources Conservation Service (NRCS) has developed a version of ecoregions called Major Land Resource Areas (MLRAs). MLRAs are much finer than most of the other types of ecoregions; for example, there are 78 MLRAs in the 13 southeastern states that are the focus of the IMP assessment project. MLRA boundaries are drawn with regard to edaphic and physiographic relationships, but are still subjective.
Image classification is a well-known form of custom grouping, based
on reflection characteristics, which results in the delineation of
similar areas within an image. The ArcInfo function
ISOCLUSTER uses a clustering technique on sampled subsets
of cells to develop reflectance signatures for subsequent image
analysis and classification. However, the technique has rarely been
applied to primary, non-spectral data outside traditional image
classification. Omi et al. (1979) used multivariate map clustering on
primary variables including steepness, drainage, precipitation, and
fault density to demarcate fire management planning zones in the
Angeles National Forest in California.
Our objective was to create custom geographic ecoregions, based on the growth of woody vegetation. Our ecoregions would be divided based on multivariate geographic clustering of 6 variables important to tree growth: annual temperature, annual precipitation, and elevation, and some soil parameters - plant-available water content, total organic matter, and total Kjeldahl nitrogen in the soil.
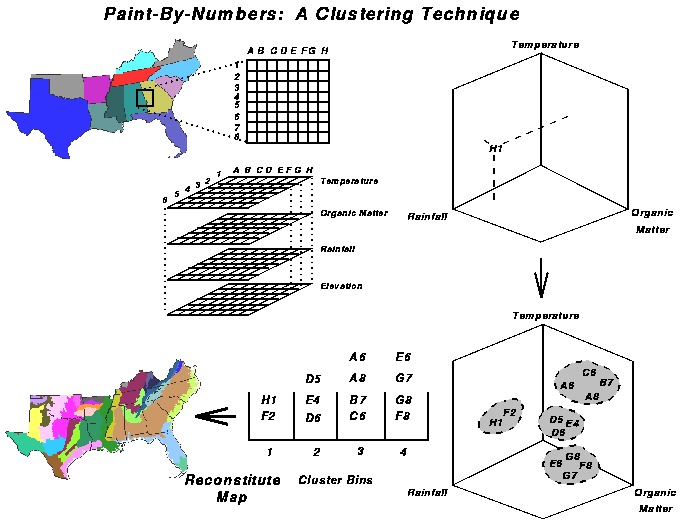
The first task is to generate maps of all variables at 1-km resolution. The clustering technique involves taking the stack of 6 co-registered maps, one for each of the variables important for tree growth, and disassemble them into their component 1-km cells, retaining the x,y position information for later re-assembly. Each cell, along with its 6 variable values, now becomes an observation in the multivariate statistical analysis. Although we used GRASS (GRASS 1993), ArcInfo GRID, Spatial Analyst, or any other raster-based GIS could be used.
The 6 values create an address for each pixel from the map in an n-dimensional volume (only 3 dimensions can be shown here). The iterative clustering procedure then divides all of the pixels in the volume into as many discrete, separate clouds of cells as the user has requested, separating them into cluster bins of pixels with similar combinations of values of the 6 initial variables. Finally, the pixels, with their cluster assignments, can be re-integrated and assembled back into the map, color-coded by cluster number.
A principal component analysis is performed on the raw data
associated with each pixel, which removes correlations among the input
variables, standardizes the mean and variance, and reduces the
dimensionality of the data set. The k-means clustering
algorithm (MacQueen 1967) iteratively changes cluster assignments until
a convergence criterion is met, and then the map is rebuilt.
Simulation models can then be run on each relatively homogeneous
cluster rather than on each individual 1-km cell. The clustered map
can be populated with simulated results cluster by cluster, like a
paint-by-number picture.
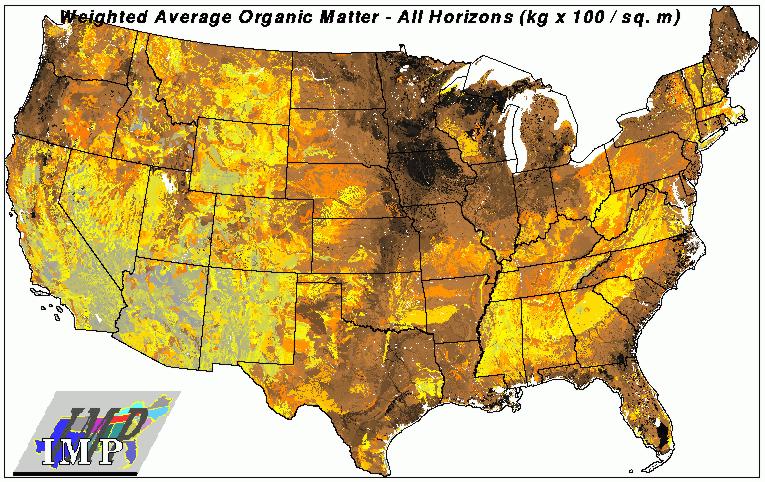
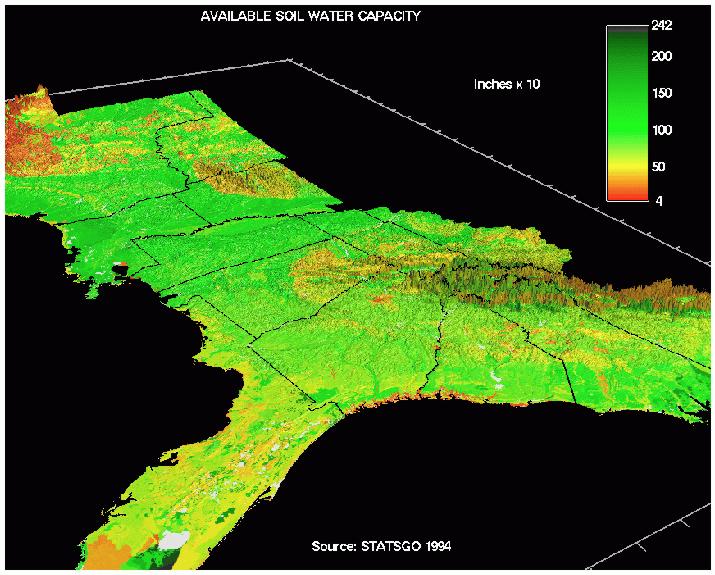
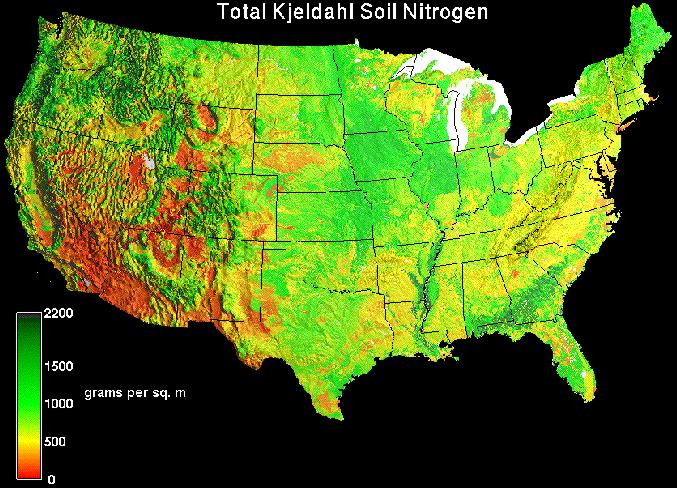
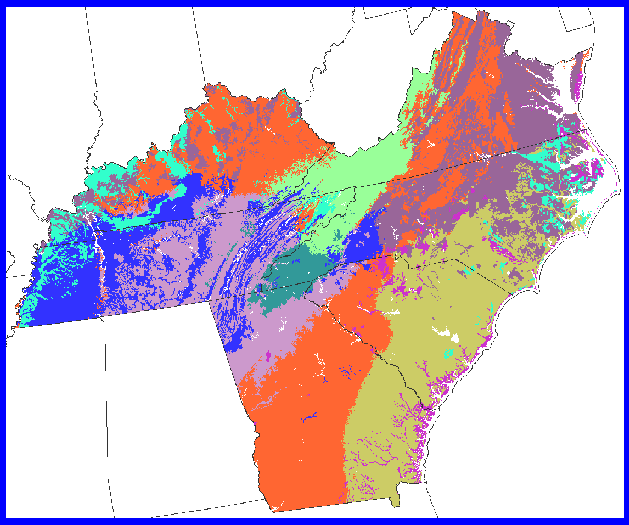
A map of total organic matter in soil at 1-km resolution nationwide was developed from the STATSGO database, developed by the NRCS. The color scale here is intuitive, from gray sandy soils to dark brown loamy organic peats. The plant-available soil water map for the 13 states, draped over elevation was also developed. Available water content is the difference between field capacity and wilting point. This map is at 1-km resolution, and was also generated from the STATSGO database. A national soil nitrogen map at 1-km resolution was developed by combining nitrogen data from the National Soil Characterization Database with spatial information from STATSGO using soil taxonomic relationships as a link. W. Mac Post was instrumental in the development of the soil nitrogen layer.
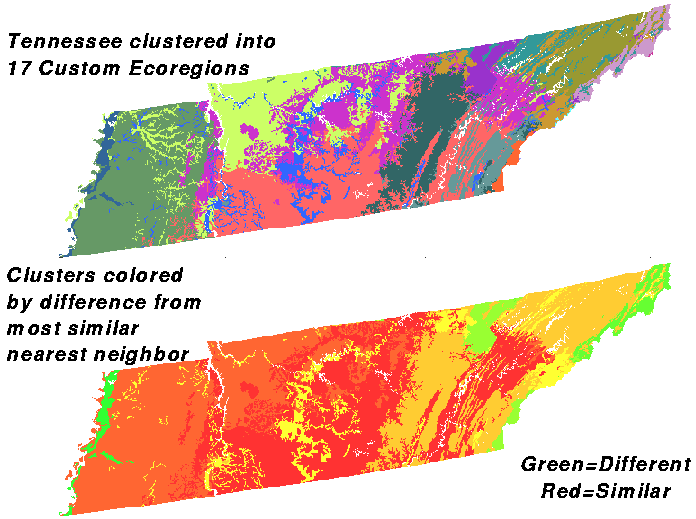
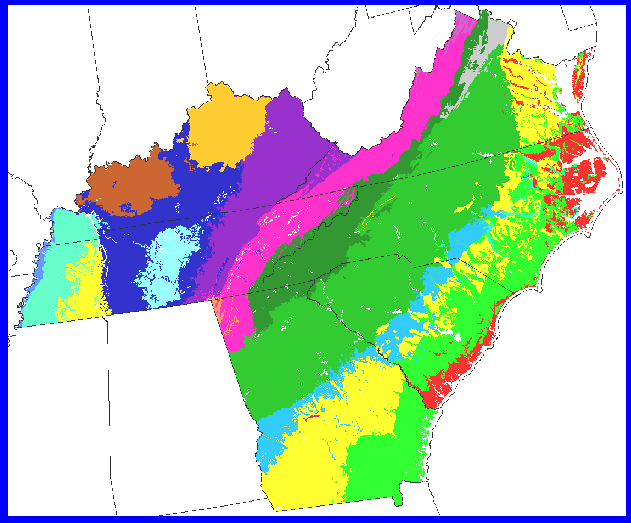
Tennessee represents an interesting diversity of MLRA ecoregions. From east to west, Tennessee has the Appalachians, the ridge and valleys, the Cumberland plateau, the Highland rim, the Nashville basin, the Coastal plain, the Mississippi sandy uplands, and the Mississippi alluvium.
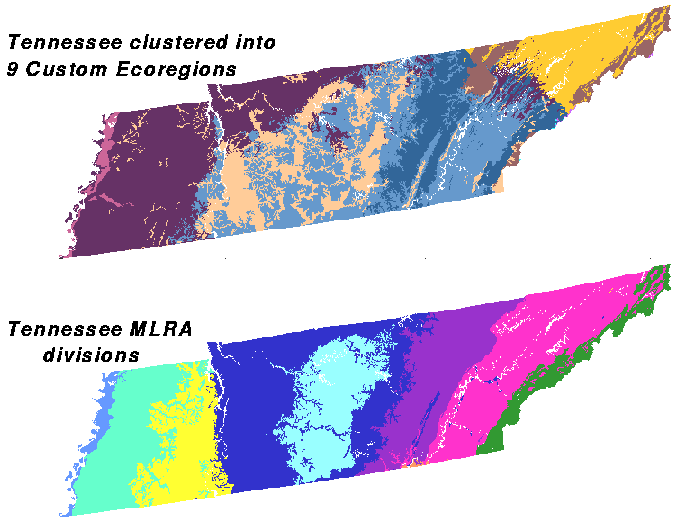
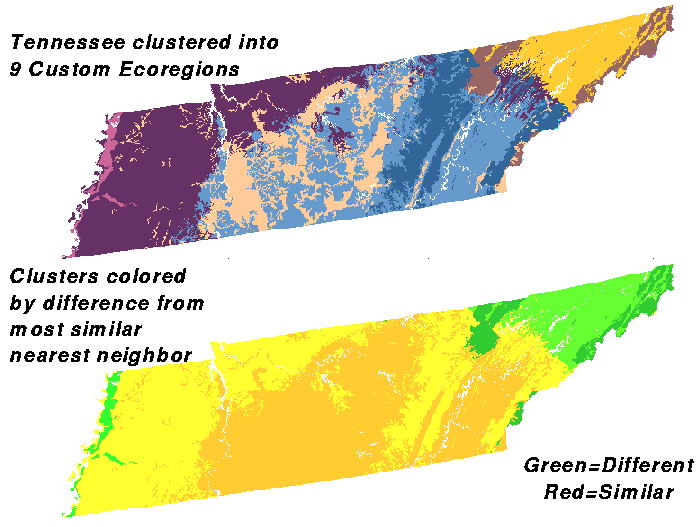
Here is Tennessee clustered into 9 ecoregions, the same level of division as the MLRAs, by the 6 variables affecting plant growth. Tennessee MLRAs are shown at the bottom for comparison. The clustering pattern is vaguely similar, but the top map is not as finely divided.
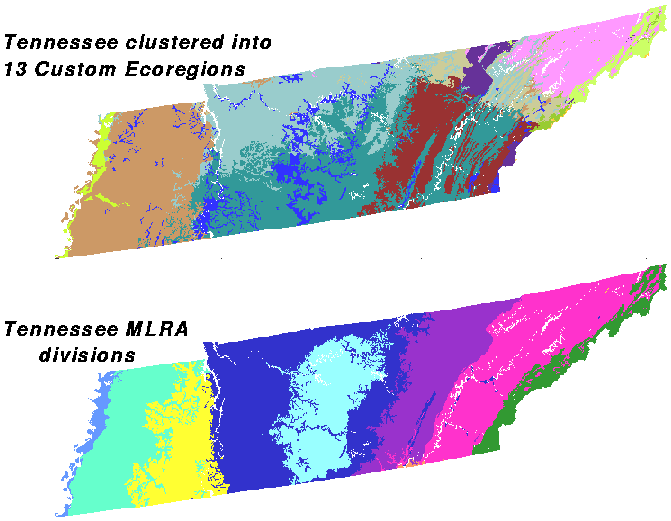
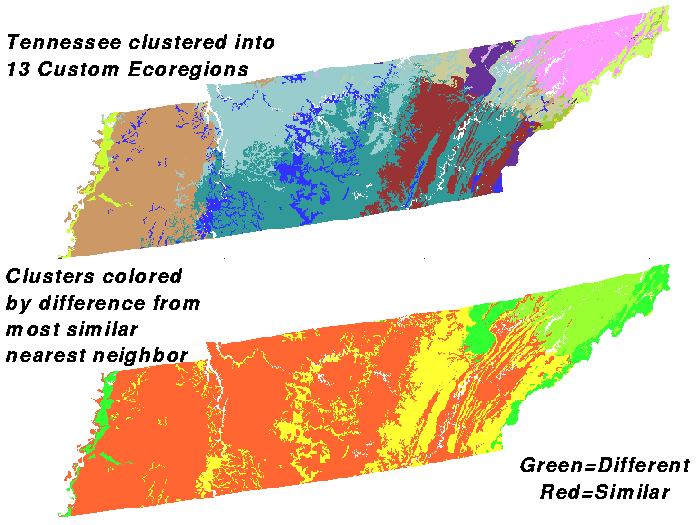
If we increase the number of divisions to 13, the top map is strongly reminiscent of the MLRA regions at the bottom. Almost all of the MLRA divisions are represented in the clustered map at the top. Although they may be more finely divided, many of the clusters share borders with the divisions between MLRA regions.
Tennessee could be split into any number of clusters. While none of those divisions would be wrong in any sense, some divisions might result in more ``natural'' clusters than others. How can we tell when we have divided an area into an optimal or ``natural'' number of clusters?
The level of division can be judged based on the similarity of the clusters that result. Every cluster has a nearest neighboring cluster in n-space; the cluster to which it is most similar. The distance from the center of the current cluster to the center of that nearest neighboring cluster will be an index of their similarity. The clusters in the map can be colored based on this similarity index to judge how ``natural'' the division has been.
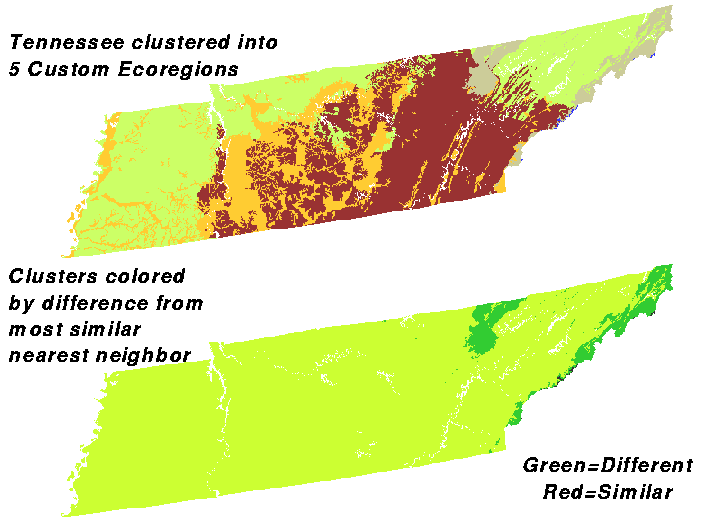
Here is Tennessee geographically clustered into 5 divisions at the top, with the same map colored by cluster similarity to nearest neighbor in n-space shown at the bottom. We see that the green clusters in the Appalachians, and the green cluster around the southern Cumberlands are very different from the rest of the state at this level of division. We will divide Tennessee more and more finely while watching the similarity maps at the bottom, all of which have the same color scale.
This is Tennessee divided into 9 clusters. Reddish clusters have started to appear in the center of the state, and the Mississippi alluvium in western Tennessee joins the northeastern tip of Tennessee as being green - substantially different from their next most similar clusters.
Here is the division into 13 clusters. There are about as many green clusters as before, but now there is more red in the bottom map. Red clusters would be the ones that would merge and coalesce if we had specified one fewer division in the map.
Here is the state at 17 divisions. Now there are a lot of red clusters, and there is less green in the map, since the greater number of clusters has reduced the average inter-neighbor distance in n-space. This probably represents a division that is too fine for Tennessee using these variables, the ideal being somewhere between 13 and 17 divisions.
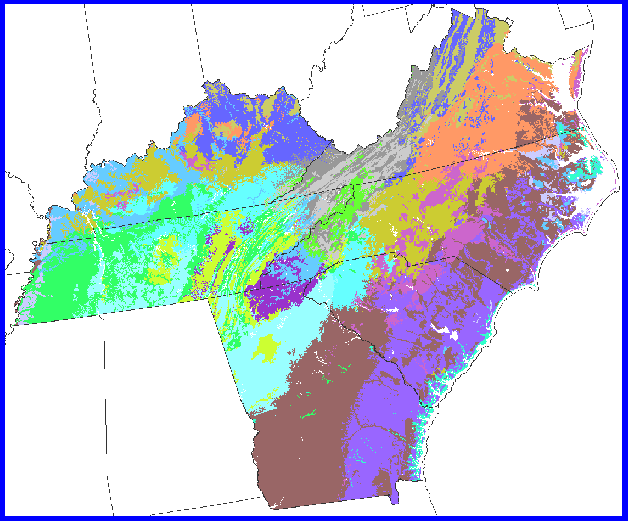
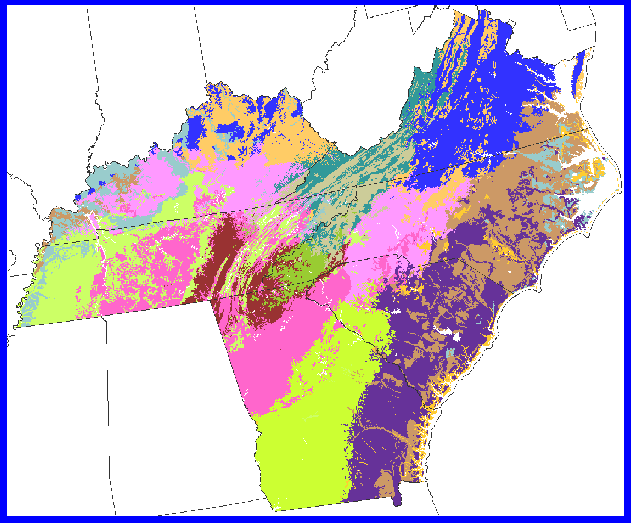
We can subject a 5 state area to the clustering procedure using the same variables to produce large-scale regional patterns of plant growth. There are 15 MLRA regions in this area. In addition to the Tennessee MLRAs, we see the Fall Line, the Coastal Plain, and the Piedmont in the south, and Pennyroyal Plain in Kentucky.
At 10 clusters, the division of the 5-state region is too coarse. Some clusters occur in more than one region of the map. This is the 5 state area clustered into 15 ecoregions, the level of division of the MLRAs within this region. While still coarse, we can see nearly all of the major divisions already; the Fall line, the Coastal Plain, the Piedmont. But the clusters are very large. 20 ecoregions reduce the average size of the clusters considerably.
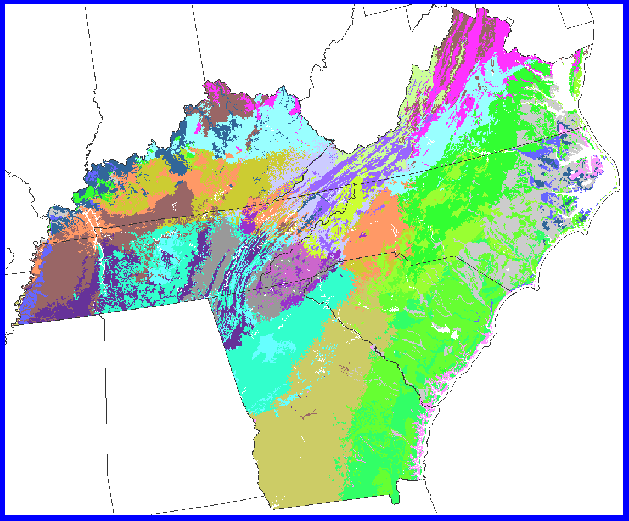
This is 25 clusters. Now we can see all of the major divisions in Tennessee, and the Smokies stand out quite strongly. The ridge and valley province, which extends from Georgia thru Tennessee into Virginia, is quite distinct. There is only 1 MLRA region for this entire ridge and valley province. But, using clustering, the ridgetops are placed in different clusters from the valley bottoms, in a slowly alternating cascade as the province streches northward. The division resulting from clustering captures the way that trees growing on ridges and valleys would experience and react to the growing conditions in these locations.
Adding 5 more clusters, for a total of 30, results in further division of the Coastal plain into subclusters. The division of the 5 state region into 30 clusters might be too fine for some purposes.
SAS can cluster non-hierarchically, that is, into a single division of clusters, relatively efficiently for data sets with large numbers of records. Nevertheless, clustering all of the cells in a large map can be computer-intensive. A related SAS procedure generates hierarchical clustering, producing a similarity tree for all possible divisions of observations. But this tool slows dramatically when given many observations.
We have combined these two tools in a strategy in which we over-divide once into many small clusters, and then recombine the small fragments together according to the similarity tree until the desired number of clusters is reached. This technique only requires performing the actual time-consuming clustering once. All subsequent divisions are obtained by lumping the finely split pieces back together.
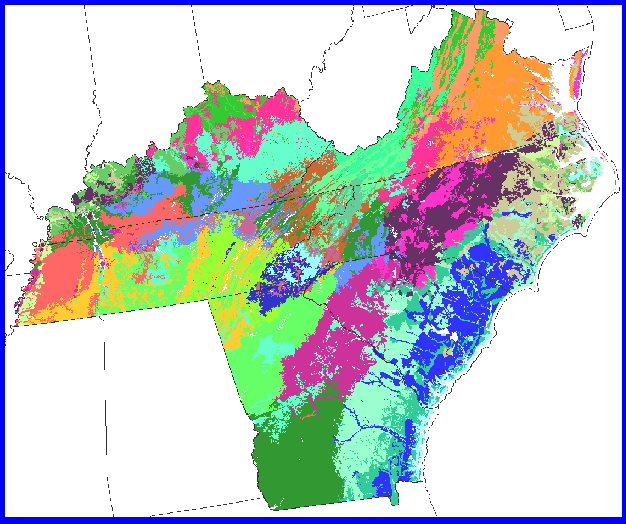
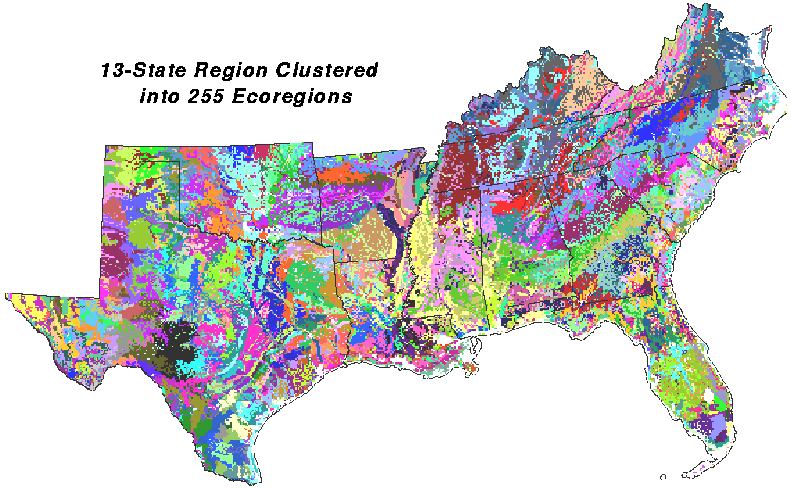
Here is the 13-state IMP region clustered into 255 ecoregions on the 6 tree growth variables. This overly-divided patchwork looks a little like fruit salad, but, even when divided this finely, most clusters emerge from n-space as geographically contiguous patches rather than disconnected speckles across the map. The 13 state area was clustered at 5-km resolution because of the extremely large number of cells (2.2 million) present at 1-km resolution.
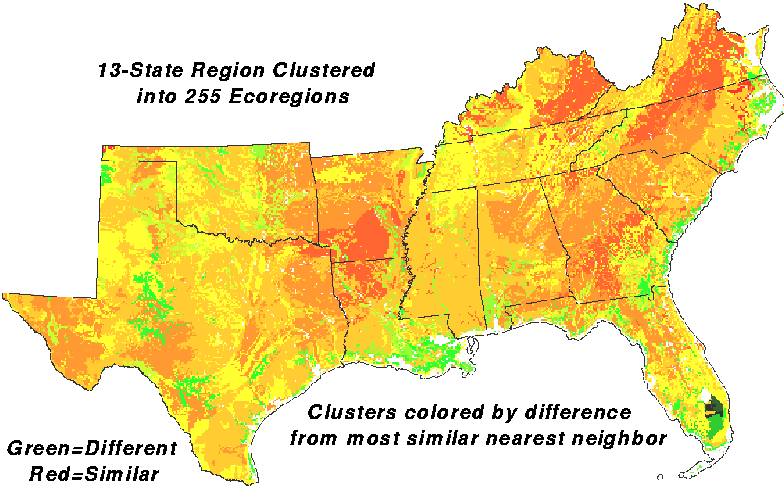
Regions are more interpretable when the 255 clusters are colored according to cluster similarities. As before, green is similar and red is different. The Everglades, the Okeefenokee, and the Mississippi delta for example, form clusters that are very different from their next nearest neighbors.
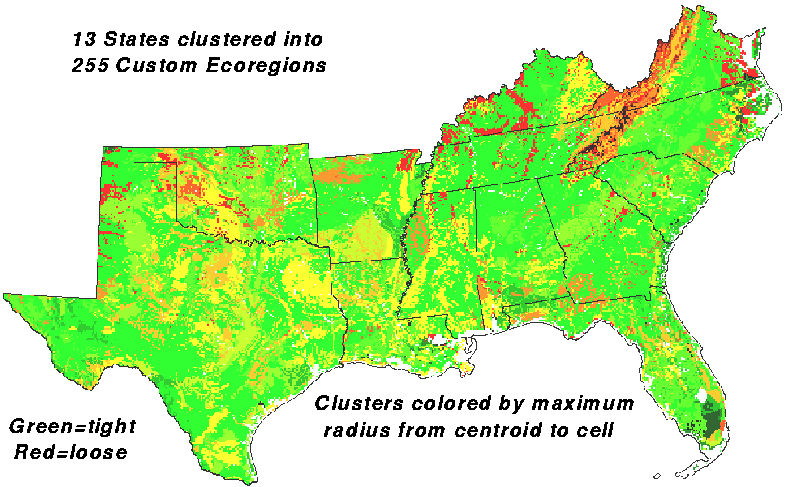
The 255 cluster map can be color-coded one additional way - to show cluster variance. In this map, each cluster is colored by the radius from its centroid to its farthest member cell. This is a measure of cluster variance, with green for tight clusters and red for high variance loose clusters in n-space. The Everglades are relatively uniform, forming a tight green cluster, while the Appalachians are more heterogeneous, forming a red cluster.
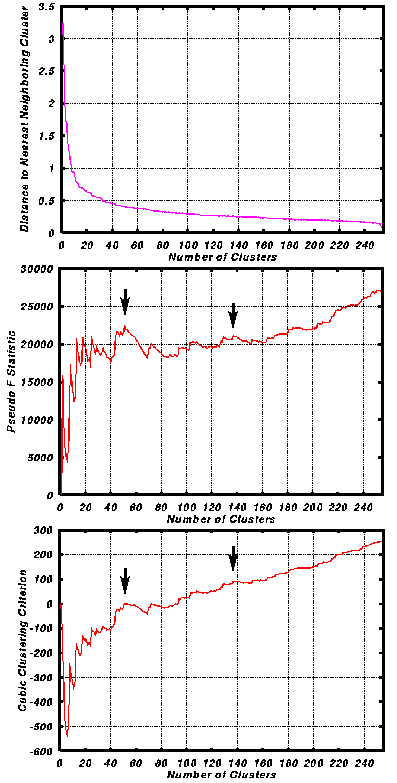
Hierarchical clustering provides some pseudo-statistical indices which can be used to judge natural clustering divisions. In all 3 of these graphs, the horizontal axis is number of clusters, from 0 to 255. The top graph shows that nearest-neighbor distance drops assymptotically as cluster number increases. The middle graph shows a Pseudo F statistic, and the bottom graph shows the Cubic Clustering Criterion with increasingly fine divisions. The inflection points in the curves for these statistics show natural divisions occuring at 51 and 136 clusters, as indicated by the black arrowheads.
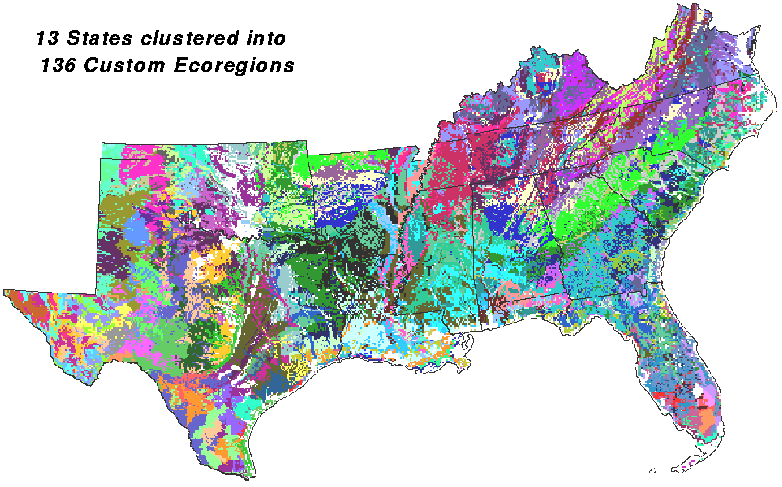
The 13 states with their 255 clusters can be lumped back together by the similarity tree into the natural grouping at 136 ecoregions. This division is finer than the 78 MLRAs for this area, and is finer than any existing set of ecoregions.
Here the similarity tree has been used to lump the 255 original clusters back down to 51 ecoregions. This division is slightly coarser than the 78 MLRAs within this region.
This multivariate geographic clustering technique has several advantages. Clustering is data-driven and empirical. This objectivity means that one obtains the same result every time, given the same data and a request for the same number of clusters. This is in contrast to regions drawn by expert opinion. Users control what data are included for consideration in the clustering process based on what is appropriate for their purposes. Users are also able to select how many homogeneous regions are produced in the final clustered map. Finally, any eclectic combination of continuous variables can be combined to form homogeneous areas on a map. Map clustering is a technique that invites the simultaneous geographic comparison of apples and oranges.
Bailey, R.G. 1983. Delineation of ecosystem regions. Environmental Managemant 7:365-373.
Bailey, R.G. 1995. Description of the ecoregions of the United States. (2nd ed., 1st ed. 1980). Misc. Publ. No. 1391, Washington, D.C. U.S. Forest Service. 108 pgs with separate map at 1:7,500,000.
Bailey, R.G. 1996. Ecosystem Geography. Springer-Verlag. 216 pgs.
GRASS 4.1 Reference Manual. 1993. U. S. Army Corps of Engineers, Construction Engineering Laboratories, Champaign, Illinois, p. 422-425.
Holdridge, L.R. 1947. Determination of world plant formations from simple climatic data. Science 105:367-368.
MacQueen, J.B. 1967. Some methods for the classification and analysis of multivariate observations. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability 1:281-297.
Omi, P.N., L.C. Wensel, and J.L. Murphy. 1979. An application of multivariate statistics to land-use planning: classifying land units into homogeneous zones. Forest Sci. 25(3):399-414.
Research sponsored by United States Forest Service Southern Global Change Program under interagency agreement with U.S. DOE. Research conducted at Oak Ridge National Laboratory, managed by Lockheed Martin Energy Corp. under contract DE-AC05-96OR22464 with U.S. DOE.
"The submitted manuscript has been authored by a contractor of the U.S. Government under contract No. DE-AC05-96OR22464. Accordingly, the U.S. Government retains a nonexclusive, royalty-free license to publish or reproduce the published form of this contribution, or allow others to do so, for U.S. Government purposes."
For additional information contact:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}